Delivery and processing semantics: overview
In this article I want to make an overview of a delivery semantics in messaging systems, describe delivery guarantee and add my own thoughts about all of this.
Table of contents
Delivery semantics: overview
So, what exactly is delivery semantics and why this is important? Delivery semantics is about guarantees provided by messaging system or delivery protocol.
These guarantees are about message order (delivery and processing), delivery reliability, duplication allowance and so on. In other words delivery semantic determines how exactly message will be handled in terms of delivery.
Why this is important? Before answering this question, I will start with a few examples.
Imagine that we develop a system which scrape metrics from other services.
Our system will scrape metrics from each service with some predefined interval, for example, each 15 seconds. After scrapping out system will save these metrics in some storage for future processing.
Each scraped metric is a message.
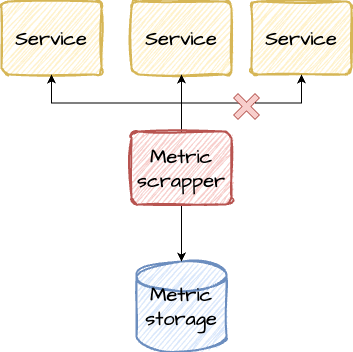
Assume that other services are not super critical and if metric extraction attempt wasn’t successful world will not collapse.
In this case we can allow our system to lost some messages because we know that another attempt will be made in the next 15 seconds.
Such guarantee is called at most once.
Now assume that we develop a part of a big e-commerce product which responsible for generation and sending of some kind of confirmations like purchase or delivery.

Sending confirmations is an important process, and we cannot allow our system to lost messages. Each lost message means that customer may not get a confirmation about purchase or delivery, which can lead worsen user experience.
Because of it we made a decision that our service will retry confirmation sending until we are 100% assured that confirmation is sent.
This guarantee is called at least once. As you can see this guarantee already add more complexity in our service because now we have to concern about retries and also we have to store some state for it (otherwise how we know what should be sent?).
The last example will be a banking system which responsible for transactions.

In this example there is some money transfer service which responsible for a full transaction cycle:
- Get money from first user’s account
- Add money to the second user’s account
Each step must be done exactly once, otherwise we will have inconsistent state:
- If money will be withdrawn twice from the first user’s account, then this user will lose some money
- If money will be added twice to the second user’s account, then, probably, second user will be happier than usual as he will get more money, but, at least, it will definitely affect net income
Also, both problems, at worst scenario, may cause problems with regulatory.
To guarantee that everything goes well our money transfer service must do both operations strictly one time. Such guarantee is called exactly once.
These examples showed that globally there are three guarantee types:
at-least-once– some messages may be lostat-most-once– some messages may be duplicatedexactly-once– no messages lost and no messages duplicated
So, why delivery semantic is important? Why we can’t just always select the highest guarantee and develop every system where everything processed exactly-once?
As you can see from examples above, different scenarios require different solutions. Also, the higher guarantee you choose, the higher the cost of development in terms of complexity.
In the next paragraphs I will explain each guarantee more profoundly. After that we will discuss end-2-end delivery and processing.
At-most-once
At-most-once is the weakest message delivery guarantee. As we already know services which implement it may lose messages, but they shouldn’t produce duplicates.
In real live services may as lose messages as produce duplicates of them, but let’s imagine that only message lose is possible for now.
So, globally we have two situations:
- Message was delivered successfully
- Message was lost during delivery
There are other scenarios where message may be lost, but, again, for now imagine that our consumer always handle messages correctly if at least get them.
First case is happy-path and shown in the next picture:

Here producer produced message and successfully sent it to the consumer. Consumer also successfully handled it.
Unfortunately, in production systems we also have to consider not only happy-path. What can go wrong?
Actually, everything, starting from producer:
producermay don’t even send message because of different reasons (e.g. bugs)producermay send message, but network isn’t 100% reliable and message may be lost betweenproducerandconsumer
Consumer may also not be able correctly handle message due to errors, but as I defined previously, let’s think that for now consumer is reliable and always correctly handle messages.

If at-most-once is such unreliable that can lose messages why it even exists?
There are multiple answers for it:
- Special requirements
- Implementation simplicity
Special requirements mean that some systems have requirements like delivery speed and ability to continue delivery rather than reliability.
A classic example is VoIP (Voice over IP) services. Such services use UDP to transfer data. UDP is a transport protocol that does not guarantee
delivery of packages (order and absence of duplicates are also not guaranteed), but using of this protocol allows continuing to receive new data (or voice in this example).
At the end, repeating last sentence(s) to your companion is not a big deal in comparison with a stopped call.
What about simplicity? Simplicity in case of at-most-once means that it may not implement retries, may not support ordering and may just send and forget.
Such systems are much easier to implement, because of almost no delivery guarantees.
Believe me, this is a miracle if you can choose this guarantee, but it’s an uncommon case, at least, in my practice.
Now let’s move on to the next guarantee: at-least-once.
At-least-once
The at-least-once guarantee as we already know declares that no message will be lost, but some messages may be duplicated during delivery.
Usually it means that producer will not move on to the next message until consumer or any other system acknowledge that previous message was successfully delivered.
In which cases duplication may happen? If we consider only delivery part, then it may happen if producer sent message but didn’t get acknowledge. In this case producer should retry delivery.
Another example is network problem: producer sent message and consumer successfully got it, but when consumer tried to send acknowledge something went wrong during network communication.
The same may happen during producer sending if, for example, network connection was lost after sending. This will also lead to delivery retry.

This guarantee requires that producer should track if message was successfully sent or not. In most cases this is not a problem,
but this may affect throughput and decrease it.
As for example you can consider TCP protocol. Previously we discussed that UDP works in fire and forget mode. TCP on the other hand
tracks each packet and if something went wrong then it automatically re-send lost packet. But you may ask if TCP re-send packets why it doesn't lead to duplication of whole messages?
Looking ahead, this is because consumer correctly process it. It will be described in the next chapters about processing semantics and end-to-end guarantees.
And finally let’s consider exactly-once.
Exactly-once
Exactly-once is the most strict guarantee because it requires that each message will be delivered exactly once.
It’s also the most complex guarantee for developing because software system should account a lot of things which may lead to message lose and duplication
and such system should also have ways to overcome them.
If we only consider the delivery part, can we really guarantee that the actual delivery will happen exactly-once? In my opinion, no.
I am convinced that the producer can’t guarantee that it will send the message exactly-once. It is just not possible, because a lot of things may go wrong.
What if the consumer responded with an error and required a retry? This is already a duplication in terms of delivery.
Another case is network problems again: in such cases the producer has to re-send the message because it cannot determine whether it was sent or not:
- If the
producerjust move on and continue sending the next messages then some messages may be lost. Messages may be lost only if we use theat-most-onceguarantee. - If the
producerretry to send already successfully sent message then it may produce a duplicate and this is theat-least-onceguarantee.

So, if this is not possible then why some systems declare that they support it? The answer is that such systems mean end-to-end delivery and processing.
Before we will talk about the end-to-end guarantee let’s look at the processing guarantees that lie on the consumer side.
Processing semantics: overview
Previously we’ve talked about delivery guarantees and consider that there is some producer which produce messages and some kind of consumer or even reciever that get these messages.
We defined such communication between producer <-> consumer as a delivery and said that consumer is 100% reliable and always process each message correctly. But is it true?
In a real production systems consumer whatever it is also may produce some errors which may lead to message processing inconsistency. Let’s dive deeper in it and consider the already known semantics but from another perspective.
At-most-once
Again we will start from the weakest guarantee. Imagine that we have some message broker (Kafka, RabbitMQ, ActiveMQ, etc.) and we want to read and process some messages.
For it, we will use a consumer which will ask a broker for the next message (let’s consider that messages come one by one). Each message should be processed by the consumer and processing must be acknowledged.
For simplicity, we also assume that communication between the message broker and the consumer in terms of network is reliable and may not produce any error. It will help us to concentrate only on processing step.

Ok, the consumer got a message, acknowledge it and then process it. Is this pipeline reliable in terms of guaranteed message processing? Answer is no.
The reason is we acknowledge message processing before the actual processing. Everything may happen between this two steps and any error may lead to message lost.
But in terms of message processing this is called also at-least-once processing.
The reasons why such guarantee exists almost the same as for at-least-once delivery:
- Special requirements
- Implementation simplicity
Such processing is really simple in terms of implementation and may be useful in some systems which require low latency message processing rather than message processing guarantee.
But what if we don’t want to lose any messages? For this we need another processing guarantee called at-least-once.
At-least-once
At-least-once processing like at-least-once delivery means that each message may be processed one or more times.
Let’s consider a notification service. This service should get task from a message broker and call notification provider to notify an end-user about some event.
In this case our service does:
- Get message
- Try to notify end-user using external notification provider
- If notification was sent successfully then acknowledge message processing otherwise throw an exception and repeat form the start

In case of error in the worst case we not only just read our message second time, but we also may send notification twice (and be billed for it twice).
This is called at-least-once pocessing because we may process each message more than one time, but this give as a guarantee that no message will be lost in terms of processing.
Using message broker this is not hard to achieve such guarantee: we just need to move acknowledgement step after processing. In other systems this may require additional work, but the core idea is the same: acknowledge message processing after the actual processing.
But what if we can’t afford nor lost messages nor duplicates? Is it possible? Actually, yes…but with nuances.
Exactly-once
So, imagine that you have successfully setup message producer which generate some messages into our broker. We know that producer doesn’t lose messages and never produce duplicates.
And we want the same for our consumer. How to achieve exactly-once processing?
Let’s consider a consumer which should save some received data into database. Again, we don’t want nor duplicates nor data loss. Generally, processing will look like this:
- Get message
- Save into DB

And we have two options for acknowledgement:
- Before saving into DB
- After saving into DB
If we acknowledge message processing before saving into DB then we will get at-most-once processing which may lead to message loss.
If we try to acknowledge message processing after saving into DB and then out application fail then we will process this message twice which lead to duplicates.
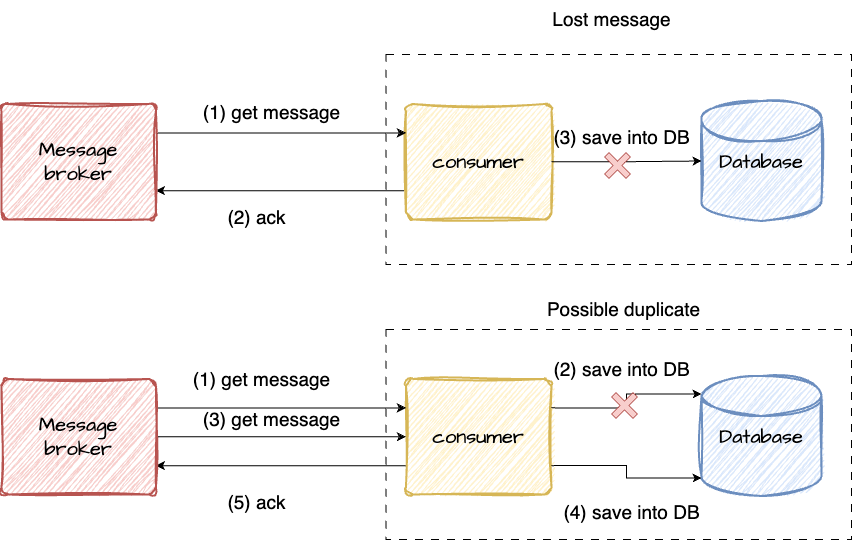
So, how we can guarantee exactly-once processing? The answer is: this is impossible. But in previous paragraph i said that it is actually possible with some nuances.
If we can’t guarantee absence of duplication then we should rely on something which can allow us to achieve this:
- Deduplication
- Idempotence
These properties regard mostly the message processing logic, nor message consumption. In general, it means, that you can’t be assured that message consumption is always consume message and never lost it and never make duplicates, but you can guarantee that your logic either is idempotent or your logic does deduplication.
Let’s consider both cases on examples. We will start from message deduplication. Again, we assume that we have some message consumer which should just save received messages into DB, and we don’t want duplicates.
How to achieve this? If each message contains unique identifier then we can use some kind of UPSERT logic and guarantee that this message will be represented strictly as one unique row in final DB. Here the responsibility for the deduplication lies with the DB.
But what about idempotency? Idempotence is a property which means that despite the number of calls of the function and if we don’t change input parameters then we will always get the same result.
Simple example is x * 1 = x. This operation is idempotent because is doesn’t matter how many times you will do this multiplication, you will always get the same result.
Let’s consider more practical example. Imagine you have a REST API with a PUT method which change status of a task. In this case, it doesn’t actually matter if you try to call this method multiple times because actual status change will happen only on the first call. Other calls will just do x -> x.
E2E delivery and processing
So, for now we’ve observed both delivery and processing semantics, and we are ready to talk about end-to-end guarantees.
In real systems, when you will talk about delivery or processing guarantees usually you will mean end-to-end guarantees.
We will skip at-least-once and at-least-once and concentrate on exactly-once.

Here we have producer, consumer and some logic. We want to make this pipeline exactly-once in terms of message processing.
We already know, that producer may produce duplicates and consumer may read messages twice or even more times.
But we also know that we can achieve exactly-once guarantee on the consumer or more precisely logic using such techniques as deduplication or idempotence.

Is this a real exactly-once? Actually, no, because in the worst case we will process each message at-least-once, but we already know that at-least-once may produce duplicates.
If logic is idempotent or able to deduplicate messages, then we can sya that this is exactly-once pipeline.
There is another naming for it: effectively-once. Keep in mind that not all pipelines can achieve this guarantee. In some cases the best you can get is at-least-once.
Conclusion
So, long story short, delivery and processing guarantees are not simple concepts.
I have tried to describe each semantic using not only classical definition but also adding my own thoughts. The main idea which i want to use as a conclusion is: both guarantees should be considered simultaneously.
It will not matter if you achieve exactly-once guarantee for your producer part,
when your consumer handle each message twice or even worse can lost it.
Hope that this short overview was helpful :)